SoundHound Launches OASYS and Proves Orchestration Matters. The TTS Output Quality Gap Remains.
SoundHound Launches OASYS and Proves Orchestration Matters. The TTS Output Quality Gap Remains.
On June 25, 2026, SoundHound AI was named "Overall Agentic AI Company of the Year." The same week, news coverage highlighted the company's OASYS platform and its planned acquisition of LivePerson, a customer engagement company. SoundHound processes more than 1 billion voice queries per month across millions of deployed endpoints spanning automotive, restaurant, healthcare, financial services, and enterprise customers.
OASYS — Orchestrated Agent System — is SoundHound's agentic AI platform, launched in May 2026. The company describes it as the world's first self-learning orchestrated agentic AI platform where AI builds AI. It handles agent creation, multi-agent coordination, evaluation, and continuous improvement across digital and physical channels. It also supports multilingual deployment, persistent cross-channel context, enterprise-grade guardrails, and human escalation paths.
That is a serious piece of infrastructure. The industry needed it. And it still leaves one layer completely unaddressed: what happens to the audio output after the TTS model generates it.
What OASYS Actually Solves
OASYS solves the conversation layer. When a customer calls a contact center, OASYS decides which agent handles the request, how context carries across touchpoints, when to escalate to a human, and how the system improves over time. It is designed to orchestrate the flow of interaction — routing, intent, response generation, multi-agent handoff.
This is meaningful work. Before platforms like OASYS, enterprise voice AI deployments were stitched together manually. One team owned the speech recognition. Another owned the language model. A third handled escalation logic. Nobody owned the end-to-end flow. OASYS changes that.
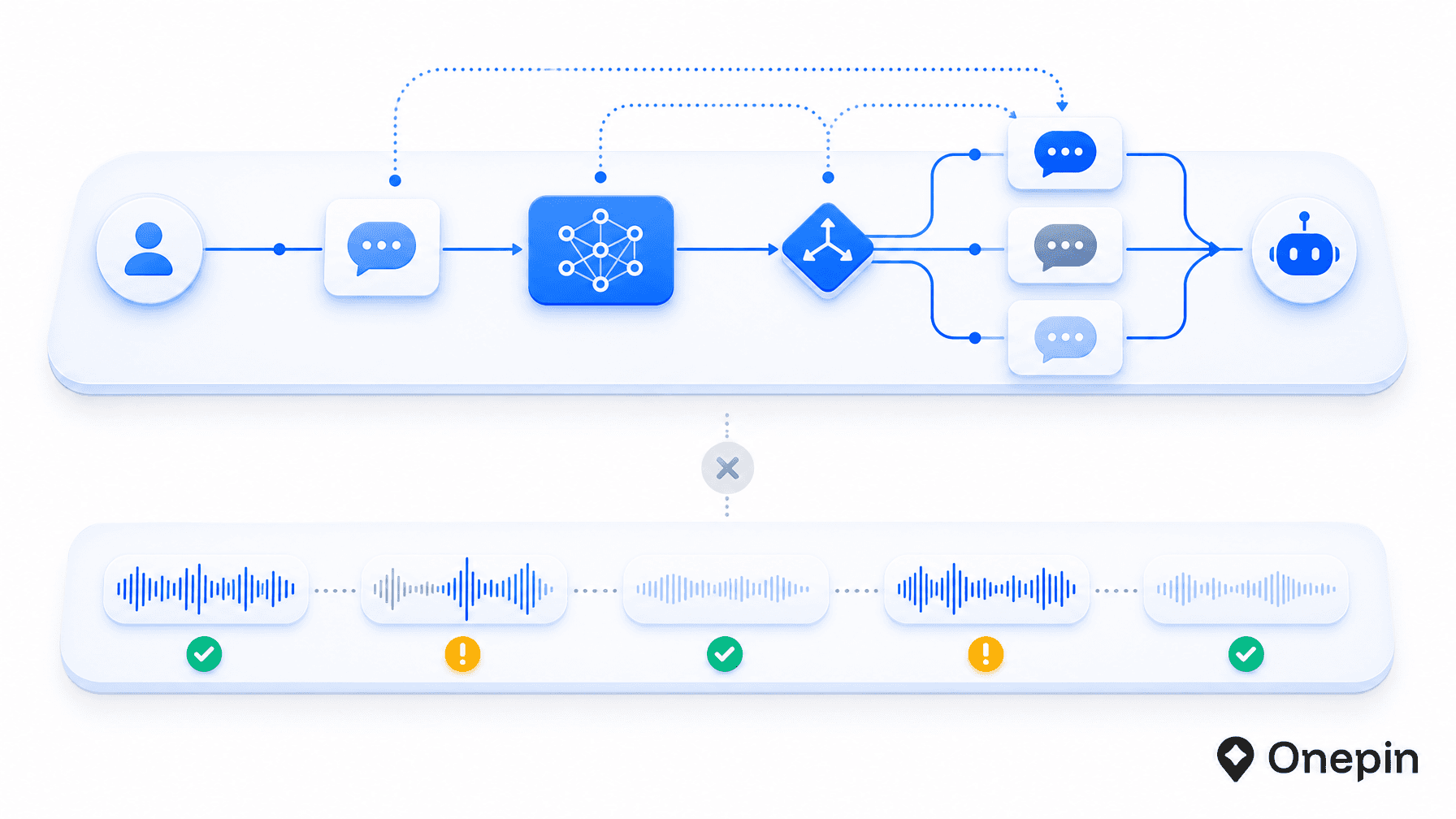
But consider what happens in a single interaction. A user speaks. The system transcribes. A language model generates a response. A TTS model synthesizes the response into audio. The audio plays back to the user.
OASYS handles everything except the last synthesis step. Once the TTS model produces an audio file, that output leaves the orchestration layer and goes directly to the user. There is no per-clip validation checkpoint. No pronunciation score. No format compliance check. No voice consistency comparison against previous clips in the same session or the same brand deployment.
The Synthesis Step Is Where Production Fails
TTS models do not fail uniformly. They fail inconsistently, and the failures are silent.
A model might pronounce brand names correctly across 9,800 of 10,000 clips and mispronounce them in the remaining 200. It might deliver clean audio in English and introduce acoustic artifacts in Spanish. It might produce audio that plays correctly on a web browser and fails silently on a telephony system that requires 8kHz G.711 encoding. Model providers update their models without changelog notifications, and the pronunciation behavior of V2 differs from V1 in ways that only surface after deployment.
None of these failures appear in conversation-level metrics. They do not affect resolution rates. They do not trigger escalation. They do not show up in OASYS's evaluation dashboard because OASYS evaluates agent performance, not audio output quality. A voice interaction can score highly on intent resolution and satisfaction while the audio it delivered was mispronounced, acoustically inconsistent, or format-non-compliant.
At 1 billion queries per month, a 1% TTS output failure rate means 10 million bad audio clips delivered to end users every 30 days. That number accumulates quietly.
Why Every Orchestration Platform Leaves This Gap
The pattern is not unique to SoundHound. Zoom's Agent Performance Suite, launched in June 2026, measures CSAT, resolution rates, and containment. It does not measure TTS output consistency or pronunciation accuracy. Patronus AI, which raised $50M earlier this year to build AI evaluation infrastructure, focuses on LLM output validation — not audio quality.
The reason is architectural. Orchestration platforms are built around conversation state and agent behavior. Audio is treated as an output, not as a data type that requires its own quality pipeline. Once the TTS call returns a file, the orchestration layer considers the job done.
This assumption worked when TTS was used for short, templated phrases. The model is deterministic for short strings. Failures are rare and easy to spot.
Modern TTS deployments are different. Long-form narration, multilingual content, brand-specific terminology, dynamic scripts with variable content — these create a distribution of outputs where failure probability is meaningful. A 2% mispronunciation rate on proper nouns is invisible at 100 clips and catastrophic at 100,000.
The Layer That Orchestration Platforms Do Not Own
A production TTS pipeline requires a validation layer that sits between the model and the end user. That layer needs four capabilities:
Pronunciation validation. Every audio clip should run against a reference pronunciation library. Brand names, product names, person names, and technical terms all require explicit validation — not spot-checking, not human review, but automated per-clip scoring.
Model version locking. TTS providers update models continuously. A pipeline validated against ElevenLabs V2 produces different output under V3. The validation layer must pin to a specific model version and trigger a re-validation event when the provider updates.
Format compliance. Audio files must meet the technical specifications of the delivery channel. A web app, a telephony system, an IVR, and an in-vehicle infotainment system have different format requirements. Generating audio that fails format compliance is a silent delivery failure.
Retake economics. When a clip fails validation, the pipeline needs automated retry logic with a quality threshold that determines when to escalate to a different model or provider. Without this, retakes are manual, expensive, and inconsistent.
None of these functions fit inside an orchestration platform. They belong in a dedicated TTS production layer.
What a Complete Voice AI Stack Looks Like
The full stack has two distinct layers. The orchestration layer — where OASYS and competitors operate — handles conversation routing, agent behavior, context, and response generation. The production layer — where Onepin operates — handles TTS quality validation, model version locking, format compliance, retry logic, and per-clip audit trails.
These two layers are not in competition. They solve different problems at different points in the pipeline. A team that deploys OASYS for agent orchestration still needs a production layer above the TTS model to validate audio output before it reaches the user.
SoundHound's ambition to process billions of interactions across enterprise-scale deployments makes this gap more significant, not less. At higher volume, the long tail of TTS output failures grows larger. The more endpoints a platform touches — kiosks, drive-thrus, call centers, vehicles, smart TVs — the more format and quality requirements diverge. The orchestration layer cannot absorb that complexity. A dedicated validation layer can.
Conclusion
SoundHound OASYS is a genuine step forward for enterprise voice AI infrastructure. The industry does need orchestration platforms that handle agent routing, context persistence, and continuous improvement. That work is valuable and necessary.
But winning "Agentic AI Company of the Year" does not solve the audio output validation problem. It confirms that conversation orchestration is a solved problem worth building a company around. The TTS production layer — pronunciation validation, version locking, format compliance, automated retakes — sits outside every orchestration platform that currently exists, including OASYS.
That gap is not a criticism of SoundHound. It is a description of where production voice AI infrastructure still needs to be built.
Onepin is the TTS production layer for teams that need both. Explore what a complete voice AI stack looks like at onepin.ai.