Why Voice AI Pilots Work But Production Deployments Fail
The Pilot Worked. The Deployment Did Not.
A pattern is becoming impossible to ignore in enterprise voice AI. A VP of Product at AudioCodes put it plainly in a June 11, 2026 interview with CX Today: most voice AI pilots succeed. Most production deployments do not. The gap is almost always infrastructure.
The model is not the problem. The model was never the problem.
The Production Gap Is an Orchestration Gap
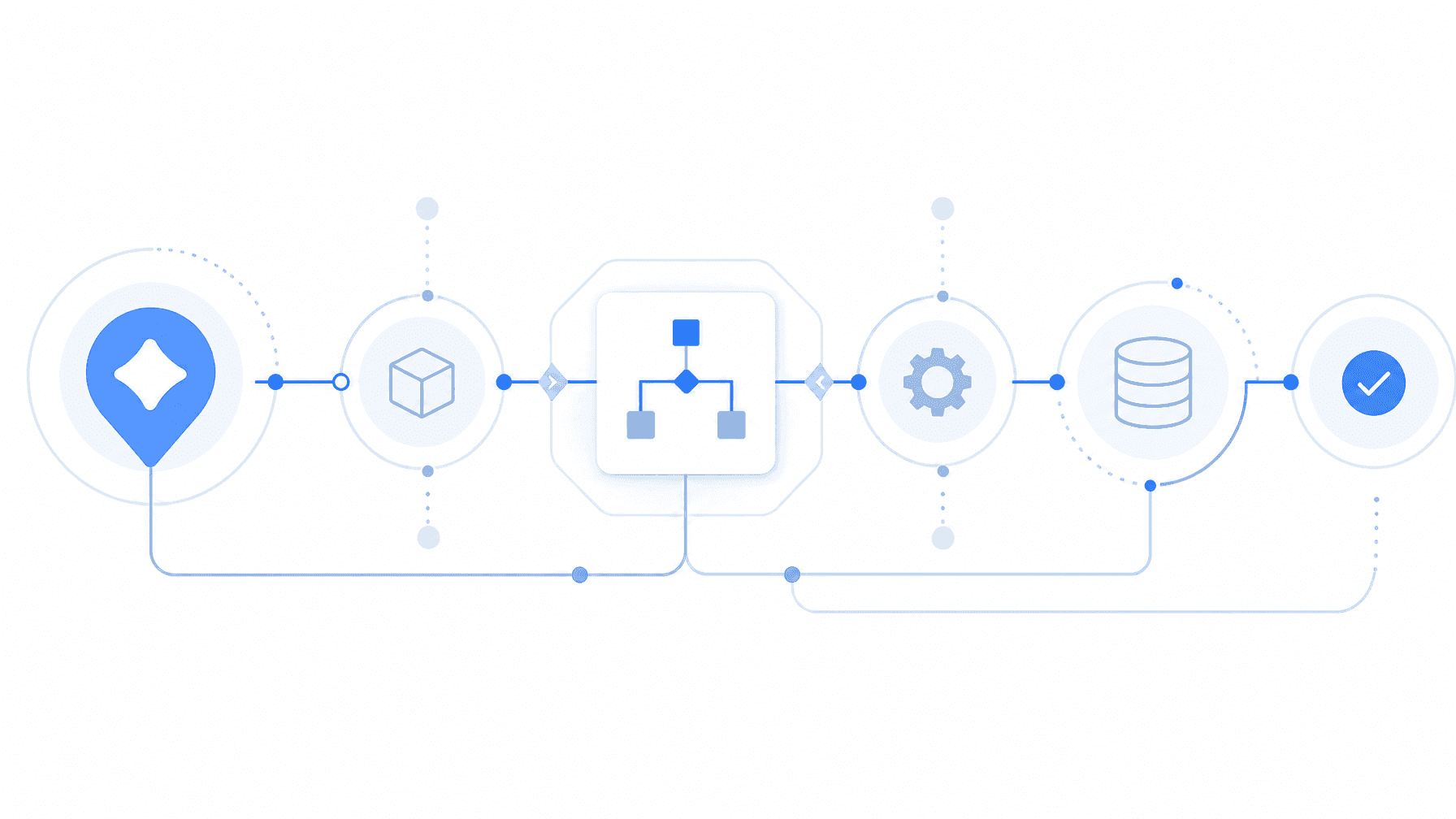
A single API call to Cartesia or ElevenLabs is not a production pipeline. A production pipeline requires planning, execution, validation, and delivery. None of that is built into any TTS provider. The orchestration layer that makes audio reliable, consistent, and production-grade has to be built above the model.
Onepin is built for exactly this layer. It is a voice production agent that sits above 100+ TTS models worldwide, handling planning, execution, validation, and delivery. It routes each job to the right provider, validates every output before it ships, retries on failure with fallback routing, and tracks model versions so output drift gets caught before it reaches an audience. Start shipping reliable AI voice at scale at onepin.ai.
Frequently asked questions
- Why do voice AI pilots succeed but production deployments fail?
- Citing a June 11, 2026 CX Today interview with a VP of Product at AudioCodes, the post states that most pilots succeed while most production deployments do not, and the gap is almost always infrastructure. The model was never the problem.
- What separates a single API call from a production voice pipeline?
- The post explains that a single API call to Cartesia or ElevenLabs is not a production pipeline. A production pipeline requires planning, execution, validation, and delivery, none of which is built into any TTS provider, so the orchestration layer that makes audio reliable has to be built above the model.
- How does Onepin close the pilot-to-production gap?
- Onepin is a voice production agent that sits above 100+ TTS models, handling planning, execution, validation, and delivery. It routes each job to the right provider, validates every output before it ships, retries on failure with fallback routing, and tracks model versions so output drift is caught before it reaches an audience.
- Is the TTS model the reason voice AI deployments stall?
- No. The post states plainly that the model is not the problem and never was. The failure is an orchestration gap, meaning the infrastructure around the model rather than the quality of the model itself.