What Is TTS Orchestration?
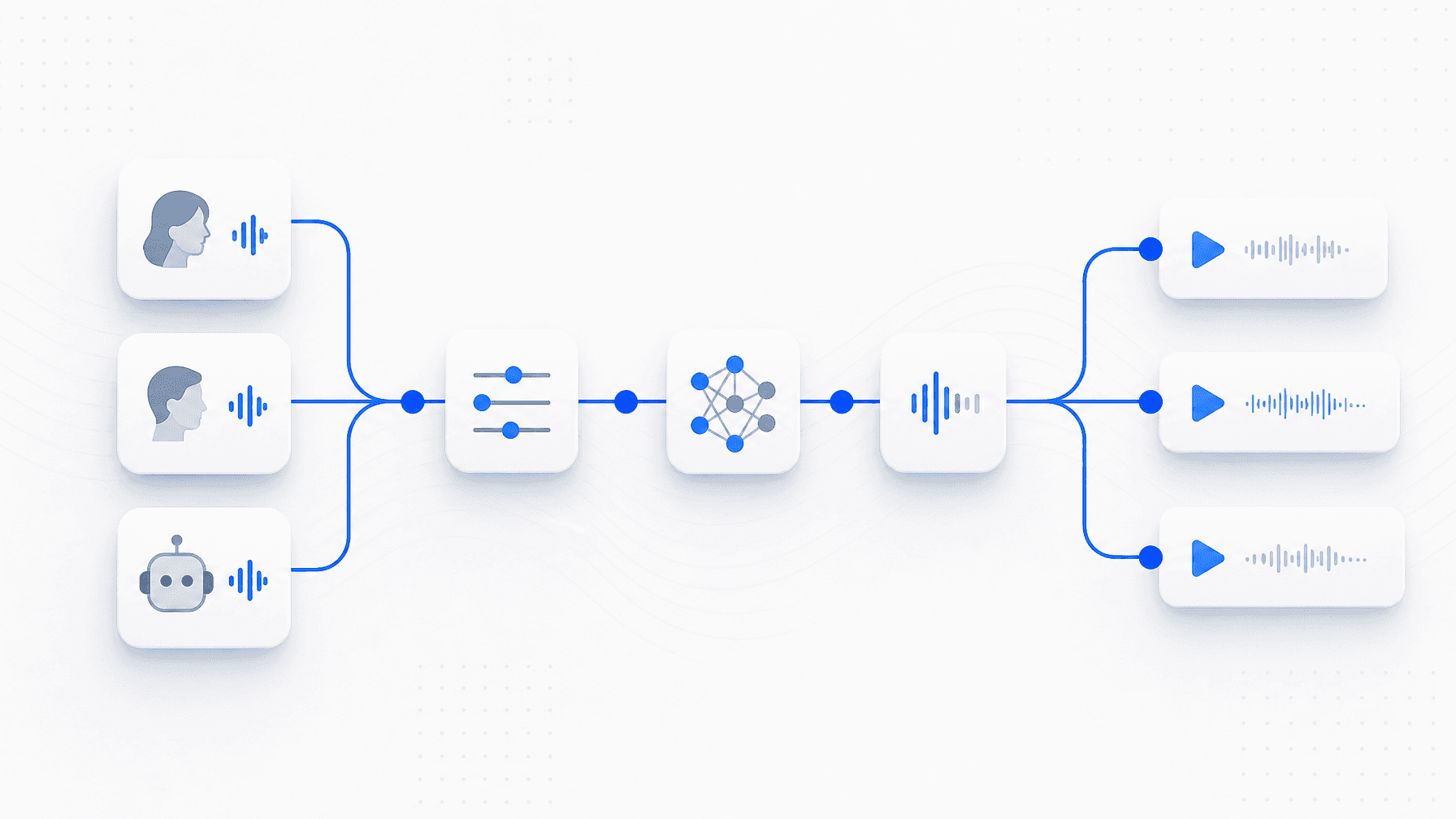
TTS orchestration is the infrastructure layer that manages text-to-speech generation across one or more models — routing each job, validating every output, and retrying on failure to deliver consistent, publish-ready audio at scale. It sits above TTS providers and treats audio production as a repeatable pipeline rather than a single API call.
TLDR
Direct TTS API calls break at production volume because of model drift, unpredictable per-output quality, multi-language fragmentation, and vendor dependency. A TTS orchestration layer addresses each with five core functions: routing, validation, retry/fallback, pipeline composition, and observability. The result is consistent audio output at any scale — without manual QA.
Why Direct TTS API Calls Break at Scale
Models from ElevenLabs, Deepgram, Cartesia, and Rime AI all produce high-quality speech. But generation and delivery are different problems. Four failure modes emerge at production scale: model drift (providers update silently), per-output quality failures (proper nouns, acronyms), multi-language complexity (each locale needs different models), and vendor lock-in (every deprecation or pricing change is a production crisis).
What a TTS Orchestration Layer Does
A production orchestration layer performs five core functions: routing (select the right model per job), validation (per-clip quality checks against spec), retry/fallback (reroute on failure, never ship bad audio), pipeline composition (decompose long jobs, manage task dependencies), and observability (structured logs per job). Onepin is a TTS orchestration agent that handles all five across 100+ TTS models. Install the Python SDK with pip install onepin or read the Onepin documentation to configure your first production voice pipeline. See the full TTS quality validation checklist for the validation standard that should accompany any pipeline.